Forecasting Divvy Bike Share Demand During Covid-19
Divvy is Chicago’s bike share system, with more than 600 stations and 6,000 iconic blue bikes across the city of Chicago. Anyone can rent a Divvy bike at a Divvy station and regular users can become subscribers to save on the price. I’ve lived in Chicago for nearly 10 years now, and in my time, I’ve noticed that most Divvy users are commuters who use the bikes to get to work or to the El, or tourists who ride the bikes downtown and along the lakefront trail. However, since Covid-19 began, I noticed an interesting trend in Divvy bikes. During my daily walks with my husband around our residential Logan Square neighborhood, I couldn’t help but notice how many Divvy bikes we saw! It was such a noticeable change and made me wonder if data science could affirm this observation. Is the way people use Divvy bikes different during Covid-19 than before?
Methodology
In order to answer this question, I obtained Divvy bike share data from the City of Chicago data portal from January 1, 2017 to August 31, 2020. In total, there were more than 13 million individual rides! Using the data, I built a PostgreSQL database and used SQLAlchemy to access the data in Python. I transformed the data to represent daily ride aggregations. Finally, I used Facebook Prophet to perform time series forecasting on daily ride demand for the remainder of the 2020 calendar year.
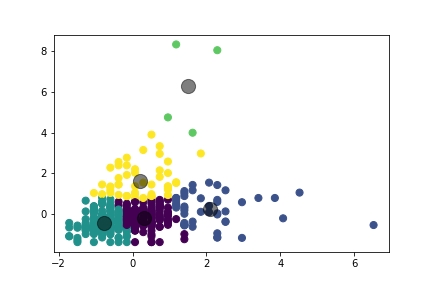
Like pretty much every area of our lives, Covid-19 had a profound impact on the way consumers use Divvy bikes. In my analysis, I found that during Covid-19 more rides take place on weekends than pre-covid 2020.
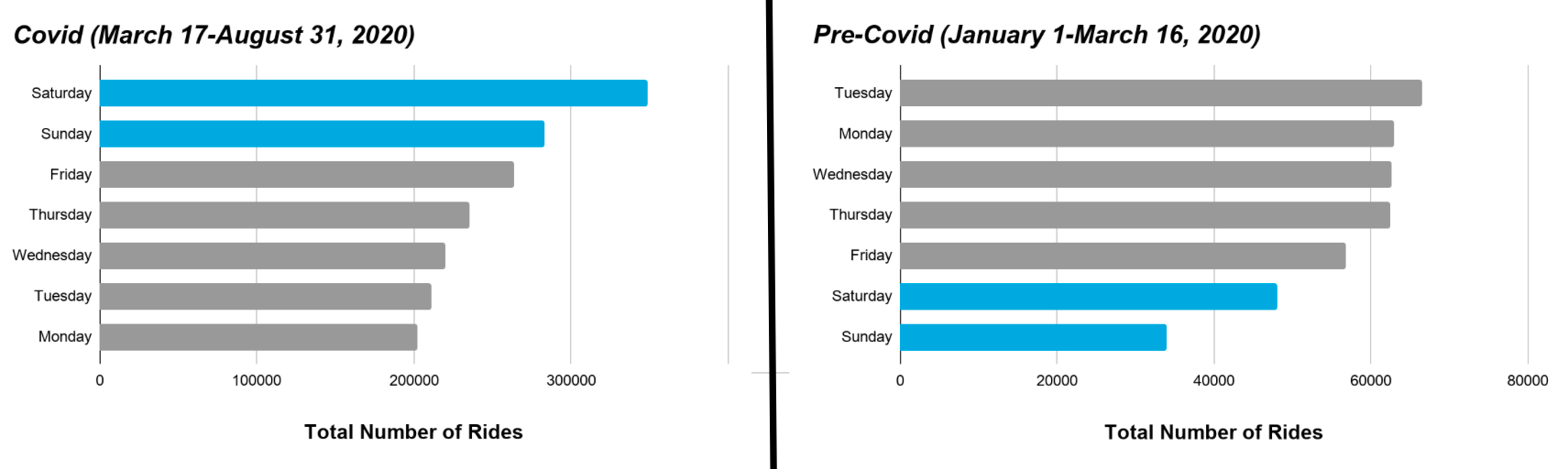
Figure 1: Comparing ride demand by day for 2020
Likewise, if we hold seasonality constant and look at the same dates from 2019, we see that weekends are still uniquely popular during Covid-19. It’s likely weekends are so popular during Covid-19 as people, likely locals, are looking for socially distanced activities to occupy their time.
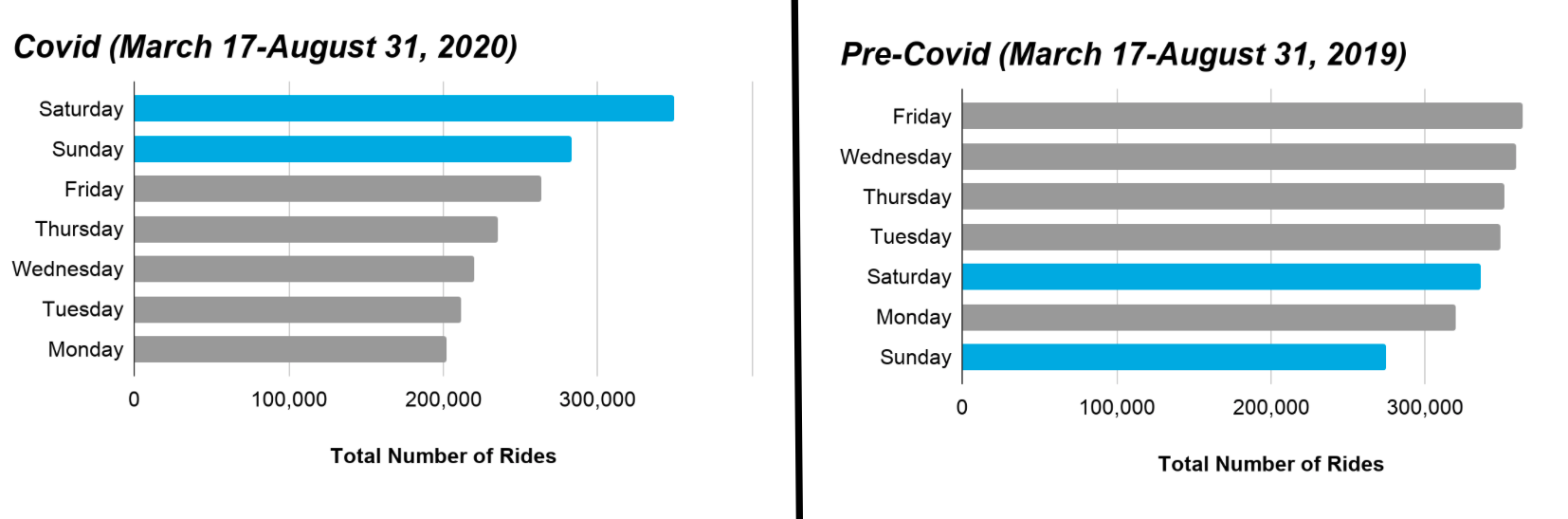
Figure 2: Holding seasonality constant, weekends are still uniquely popular
Divvy ride demand follows clear Chicago weather seasonality, with ridership spiking in the summer months and dropping in the bitter cold winter. However, in 2020, you can see that Covid-19 had a noticeable difference on demand compared to the past. Chicago followed a phased shutdown and reopening in response to Covid-19. Phase 1, which was the initial strict stay-at-home order, was from March 17-April 30, 2020. During this time, you’ll notice a sharp decline in rides. Phase 2, which was from May 1, June 2, 2020 was a continued stay-at-home order, but with safety precautions for going outside. As a result, there’s an initial increase in ride demand. Phase 3, which was from June 3-25, 2020, was when Chicago cautiously reopened. Here, there’s again an increase in ride demand. And finally, Phase 4, that started on June 26 and which is where Chicago is currently at, is the gradually resume phase where most places have opened with mask, social distancing and capacity restrictions. In this phase, for the first time since shutdown, demand is comparable to the past.

Figure 3: Sharp decline and rapid rise in bike demand in 2020 connected to Chicago’s phased Covid-19 response
Results
Given the rapid and unique changes to ride share demand brought on by Covid-19, this posed quite a challenge for time series forecasting. I chose to forecast with Facebook Prophet. Prophet is an additive model built specifically by Facebook for non-linear, seasonal data. It’s robust to shifts in trend and outliers, which Covid-19 brought a lot of. I forecasted daily ride demand across all Divvy stations in Chicago and used all data I had available from 2017 to 2020. I chose to optimize my forecasting with Mean Absolute Error (MAE) and Root Mean Square Error (RMSE) to see how many rides by model was off by each day.
After starting with a baseline, out of the box model, I added my first two Prophet custom covid seasonality: weekly seasonalities. In Prophet, a weekly seasonality is a trend in demand that repeats every week. The first weekly seasonality I created was a during covid seasonality which used dummy variables to show the unique spikes in demand on weekends and dips in demand on weekdays. On top of that, I added a pre-covid seasonality which again used dummy variables to show the weekday spikes in demand and weekend dips that were regular before Covid-19. Using just these custom seasonalities, I saw the MAE and RMS drop which meant the model had less error and was performing better. Then, I layered, custom yearly seasonalities for each phase of Chicago’s reopening. Ultimately, I was able to optimize my model by adding all covid seasonality with the exception of Phase 4. For my model, the MAE means that on average, my model was off by a little more than 2,700 rides per day.
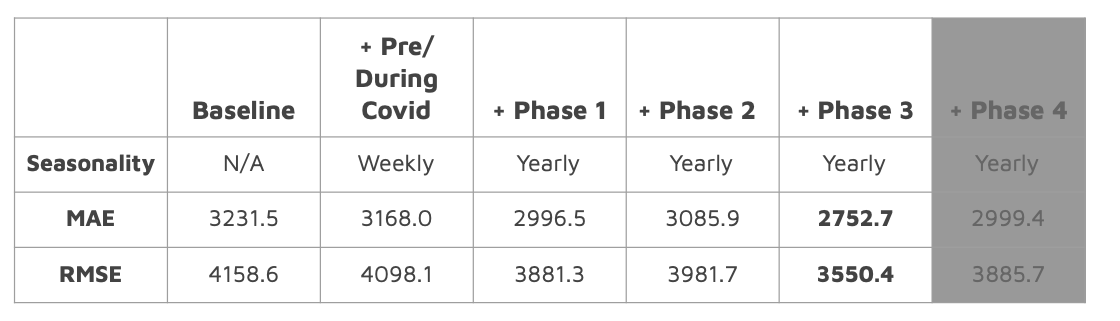
Figure 4: Error metrics for each iteration of modeling with phases
Most notably, my final model with added covid seasonality forecasts higher demand than the baseline model. This is important for Divvy to know so they can make sure to have enough bikes to meet demand in the upcoming months.
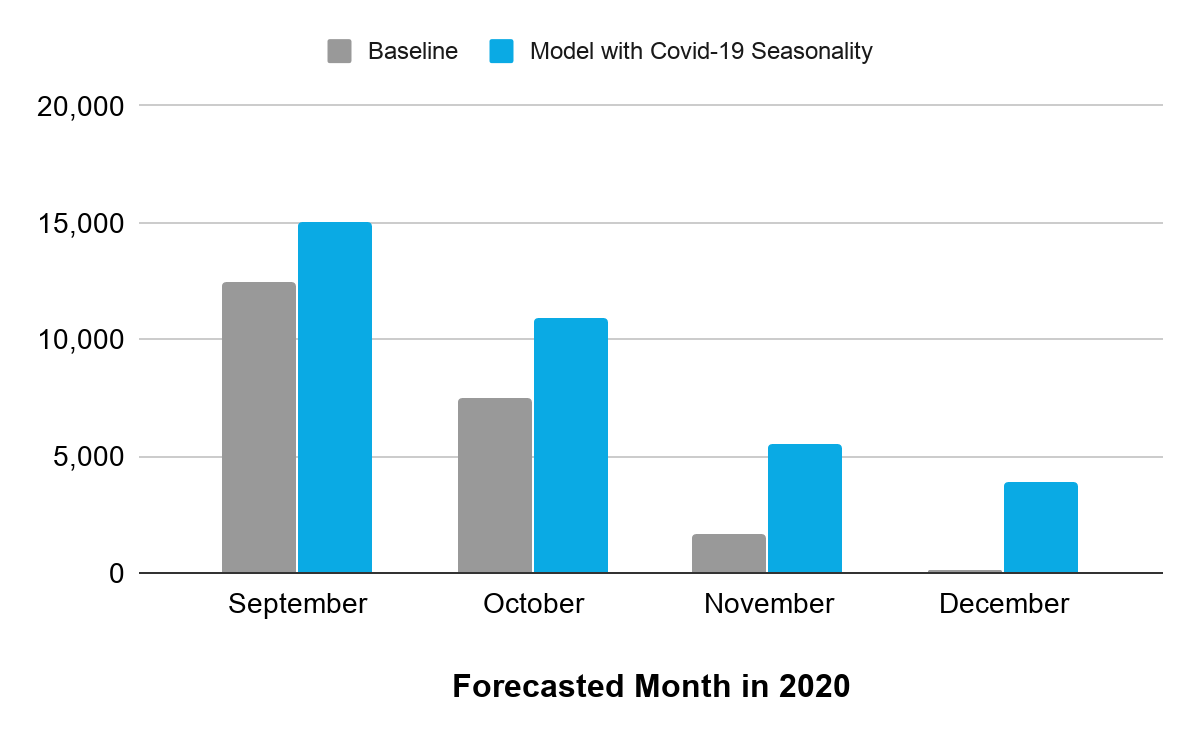
Figure 5: Model with Covid-19 seasonality forecasts higher daily demand through the end of the year
Using my analysis and visualizations I built in Tableau, I have a few recommendations to Divvy in how to address the change in demand for the remainder of 2020. First, I recommend that Divvy increase the number of bikes available in residential areas of Chicago. Rides are significantly up at stations in more densely populated residential areas, particularly along the lake and south side of the city.
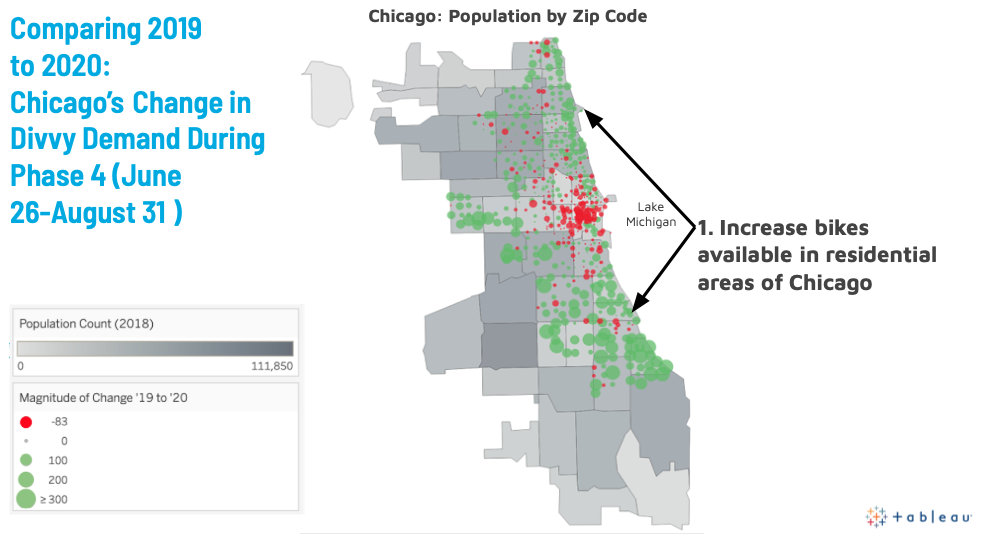
Figure 6: Demand at stations in more residential areas has increased from this time in 2019
Likewise, my second recommendation is to reduce the number of bikes available at stations in the downtown loop area, as ridership is significantly down.
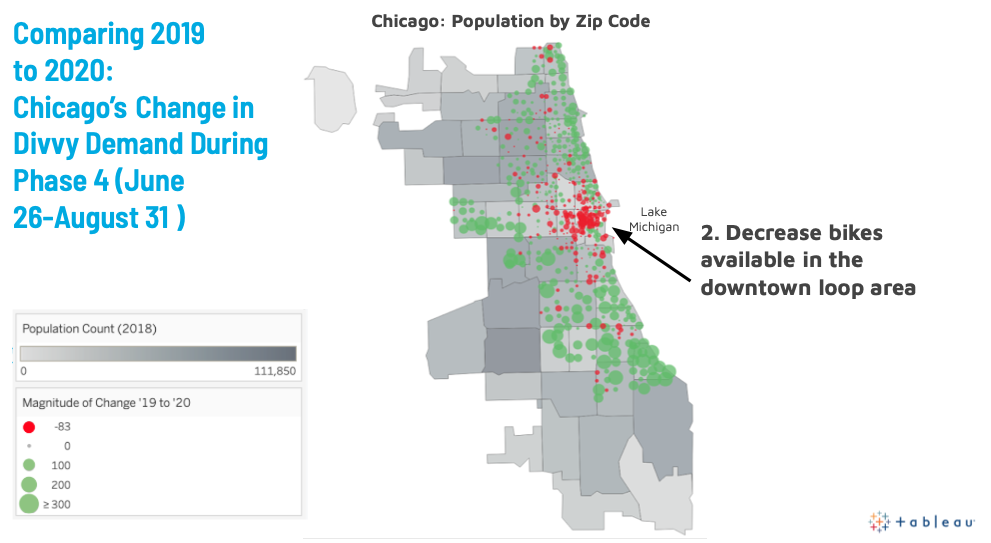
Figure 7: Demand at stations in less residential areas (downtown loop) has decreased from this time in 2019
My third recommendation to Divvy is to increase bike availability on weekends since they’re uniquely popular during Covid-19.